3年ぶりの投稿、日程調整アプリを作ってみた
3年の空白
三日坊主の性格が出ました。 はてなブログの存在を3年も忘れてました。
これまでに書いた記事を確認すると、アプリを作ったことをアピールしたくて記事を書いていることがわかる。 ということで今回もアプリを作ったので記事を書くことにします。
作ったアプリ - 日程調整アプリ「ツルんで」
前回3年前に書いた記事の中で、麻雀のハードルは同じメンバーで定期的に集まることが難しいと書いていました。 この課題は相変わらずずっと感じていて、ようやく重い腰を上げてアプリを作ることができた感じです。
アプリの紹介
いつものメンツと気軽にツルめる

やりたかったこと
以下の3つを解消するためのアプリを目指しました - 同じメンバーで集まりたい - でも毎回候補日を羅列したくない - 参加者が集まったらLINEに通知が来てほしい!
機能紹介
LINEログイン
- 「参加者が集まったらLINEに通知が来てほしい!」ということで、LINEでのログインは必須です!

- 通知のためにアプリの公式LINEを友達追加しておいて下さい!

メンバー招待機能
- 同じメンバーで調整するんだからLINEグループみたいに一緒に遊びたい人を招待しましょう!
- メンバー招待の前になんの集まりなのか決めましょう!例えば「麻雀」「テニス」などなど

- 集まりを作ったら、いよいよメンバー招待!

- 「招待リンクをコピー」してLINEのグループに貼ったらみんなカレンダーに参加してくれます!
空き時間の登録
- 「招待リンクをコピー」してLINEのグループに貼ったらみんなカレンダーに参加してくれます!
- あとはカレンダーで空いてる日、時間を登録するだけ

LINE通知機能
- 設定した人数の予定がそろったら公式LINEから通知が来ます!

みなさまご存じの日程調整ツール
- 調整さんやLINE日程調整などは幹事役の誰かがある程度の候補の日程を選択して提示するところから日程調整が始まります。
開催頻度の高くない、あらかじめ日程候補の決まっている予定の調整のために利用するにはとても便利です。
まとめ
ということで、「ツルんで」ではいつものメンツと気軽にツルめる幹事のいらないアプリをコンセプトに作成してみました。
作ったからには使ってほしいので、3年ぶりに自身のブログの存在を思い出し記事を書いてみました。 エンジニアなので作り方についても紹介したいのですが、それはまた別の記事で紹介したいと思います。
みなさま何卒使ってみていただけたらなと思います!よろしくお願いします!
麻雀をするときに便利なツールを作りたい
最近の趣味
最近の趣味は麻雀です。
今までネット麻雀だけで生きてきましたが、入社して初めて会社の先輩と雀荘に行きました。
楽しかったんですけど、非喫煙者にはタバコの煙がきつかったです。酸欠になりました。
最近禁煙の雀荘があると知って、友人と行ってみたらとても快適でとても良かったです。
できるだけコンスタントにいろんなコミュニティでリアルで麻雀がしたい。
ということで、リアル麻雀をするときに便利に使えるツールを考えてみます。
リアルのハードル
リアルで雀卓を囲みたいと思ったとき、一番面倒くさいのがスケジュール調整です。
これでも社会人の端くれなので、同級生や同期はみんないつでもOKというわけには行きません。
そうなったときにコンスタントに麻雀をできるように日程を調整できるツールが欲しいなと思ったわけです。
調整さんやLINEの日程調整って都度日程の候補を上げてみんなに共有する必要がありますよね。
なんか、曜日とかを事前に決めておいて未来の日程をどんどん更新していってくれる日程調整だと手間が省けるかなーという思いでちょっと作れたらいいなと思っています。
誰が集まるかわからない
いつもセットで雀荘に行きます。フリーで入ったことがないです。
ただ、いつも必ず同じメンバーとは限らないですよね。5人のコミュニティで4人集まる日に開催とかすると、毎回メンバーが違って得点の管理が煩雑になります。
コミュニティが複数あってもコミュニティごとにみんなで同じ得点表を見られる。そんなツールが欲しいなと思ったわけです。
もちろん日程調整のメンバーと得点管理対象のメンバーは一緒に管理できると楽ですね。
初心者と一緒にでも
麻雀面白いから色んな人を誘って見るわけです。もちろん初めて麻雀をやる人とかもいたりします。
初心者の人がまず苦労するのは役がわからないことです。余裕があれば役一覧を印刷して持っていってもいいですが、たまたま初めての人を誘ったときには用意する暇がないかもしれません。
そんなときどうせなら日程調整をするツール内で役一覧をみれたらいいなーと思ってます。
あとは、得点表も一緒に見れるようにしたいですね。負の計算よりも得点表を覚えるのが大変だと感じている今日此の頃です。
まとめ
そんなこんなで、以下の機能を持つ麻雀用ツールを作ってみようと思っています。
- 未来の参加可能な日をどんどん入力できる日程調整ができる機能
- もちろん後からメンバー追加ができる
- 日程調整をしているメンバー単位で得点を管理できる機能
- もちろん後からメンバー追加ができる
- 役一覧画面
- 点数表画面
次回以降からちょっとづつ作っていこうと思います。
上記の機能一つでもいい感じにやりたいことを満たしているアプリとかあったらぜひ教えてほしいです。
完全一致画像の検索
完全一致画像の検索
ローカルに画像が増えてきて、容量を削減したいけど画像数が多すぎてどっから消せばいいのかわからないという現象に悩まされてきたので、とりあえず完全一致している画像を検索して消すことにしました。
環境
- Windows11
- Anaconda
- Python 3.8.12
手順
もっとスマートな手順もあるのかもしれませんが、愚直に行きます。
検索対象(インプット)
大量の画像が格納されているフォルダ
検索手順
- 大量の画像が格納されているフォルダから画像ファイルの一覧を取得
- 画像を一枚ずつOpenCVを使って画像をベクトル化して画像ベクトルのリストを作成
- 画像ベクトルのリストを2重ループにして、コサイン類似度が1のものを同一画像としてピックアップして、別フォルダにコピー
処理結果(アウトプット)
類似画像ごとにフォルダ分けされたフォルダ
実装
では早速実装に移ります。
0. ライブラリのインポート
いつも特にライブラリのバージョンを意識せずにpipしてしまうので、たまに動かなかったりしますが、今回はGPUも使ってないし、特にバージョンを意識する必要があったパッケージはなかったと思いますので、足りてないパッケージはとりあえずpipで入れてください。
import os from glob import glob import shutil from tqdm import tqdm import cv2 import numpy as np import sklearn from sklearn.decomposition import PCA
1. 画像一覧の取得
# とりあえず以下の拡張子のファイルを画像とする IMAGE_TYPE = [ '.png', '.jpg', '.jpeg', '.bmp' ] # globでフォルダ内のファイルのパスを全取得する files = glob(r"image\*") # ファイル名から拡張子を取り出し、画像かどうかを判定してリストに追加する imagefiles = [] for file in tqdm(files): root, ext = os.path.splitext(file) if ext in IMAGE_TYPE: imagefiles.append(file)
2. 画像のベクトル化
# 読み込んだ画像のベクトルを格納するリスト proccessed = [] # 読み込ん画像のパスを格納するリスト imagefilenotempties = [] # 1. で読み込んだ画像のパスのリストをforループ # どれくらい時間がかかるか知りたいのでtqdmを使う for i, imgfile in enumerate(tqdm(imagefiles)): # 画像の読み込み処理 img = cv2.imread(imgfile) # imreadでNoneが返ってくることがあるので例外処理としての判定 if not img is None: # 画像ごとにサイズが違うと比較ができないので、サイズを圧縮して合わせる resized = cv2.resize(img, (64,64), cv2.INTER_LINEAR) proccessed.append(resized) imagefilenotempties.append(imgfile) print(len(proccessed)) print(len(imagefilenotempties)) # 1枚の画像に対して64x64x3のベクトルを1x12288のベクトルに変換 features = np.array(proccessed) features = features.reshape(features.shape[0], -1)
画像の圧縮を行っているcv2.resizeの引数のcv2.INTER_LINEARについては、以下の記事を参考として一番効率が良さそうだったので使用しています。デフォルトらしい? pystyle.info
3. 各画像に対してコサイン類似度を計算して同一画像をピックアップ
def similary_cossain(x, y): result = np.dot(x,y)/(np.linalg.norm(x)*np.linalg.norm(y)) return result
コサイン類似度を計算する関数を定義、以下を参考 qiita.com
# 結果の出力先を作成 resultsavepath = 'searchresult' if os.path.exists(resultsavepath): shutil.rmtree(resultsavepath) os.mkdir(resultsavepath) # コサイン類似度計算のため、各画像の次元数を2次元まで圧縮する # 特徴量を失わないようにPCAを利用して圧縮 pca = PCA(n_components=2) pcaresult = pca.fit_transform(features) # 類似画像と判定された画像を格納するリスト skipimgs = [] # ファイルパスとベクトルを同時にforループする # 類似画像検索対象を取り出す for searchfilepath, searchfeature in zip(tqdm(imagefilenotempties), pcaresult): # 既に類似画像と判定されていないか確認 if searchfilepath not in skipimgs: # 比較対象を取り出す for filepath, feature in zip(imagefilenotempties, pcaresult): # 検索対象自身でないことと既に類似画像と判定されていないか確認 if searchfilepath != filepath and filepath not in skipimgs: # コサイン類似度を計算 simi = similary_cossain(searchfeature, feature) # コサイン類似度が1ならば同一画像 if simi > 1: skipimgs.append(filepath) # 類似画像を結果出力先にコピー sameimgsavedir = os.path.join(resultsavepath, searchfilepath.split('\\')[-1].split('.')[0]) if not os.path.exists(sameimgsavedir): os.mkdir(sameimgsavedir) shutil.copy2(searchfilepath, os.path.join(os.getcwd(), sameimgsavedir, searchfilepath.split('\\')[-1])) # 類似画像検索対象側も結果出力先にコピー shutil.copyfile(filepath, os.path.join(os.getcwd(), sameimgsavedir, filepath.split('\\')[-1]))
結果
90,000枚くらいの画像で上記ソースを実行したところ、3.の処理で21時間くらいかかりました。
あまりにも効率が悪い。
3,000枚なら2分弱で終わりました。n2オーダーの恐ろしさを改めて実感。
今後
せっかく途中でPCAを挟んでいるのでk-meansでクラスタリングを挟んで比較範囲を狭めることでもうちょっと効率的に類似画像の検索ができそう。
元々は完全一致ではなく、類似画像の検索ができないかなと作ってたツールですが、現時点ではこれくらいでツールとして使えそうかなと思いましたので記事にしてみました。
とりあえず1個Webアプリを作ってみた
アプリ作成の経緯
サラリー以外の収入が欲しいと思い始める以前から、趣味でWebアプリを作っていた。
元々は自分が便利だと思ったツールを作ってみたのだけれど、どうせならみんなに使ってもらえないかなーと思いWebアプリ化してみた。
そもそものツール作成の部分を含めて、Webアプリ化に伴って色々挑戦したのでここでちょっとずつ記事にしていこうと思います。
作ったWebアプリ
作成したWebアプリはこんな感じ。
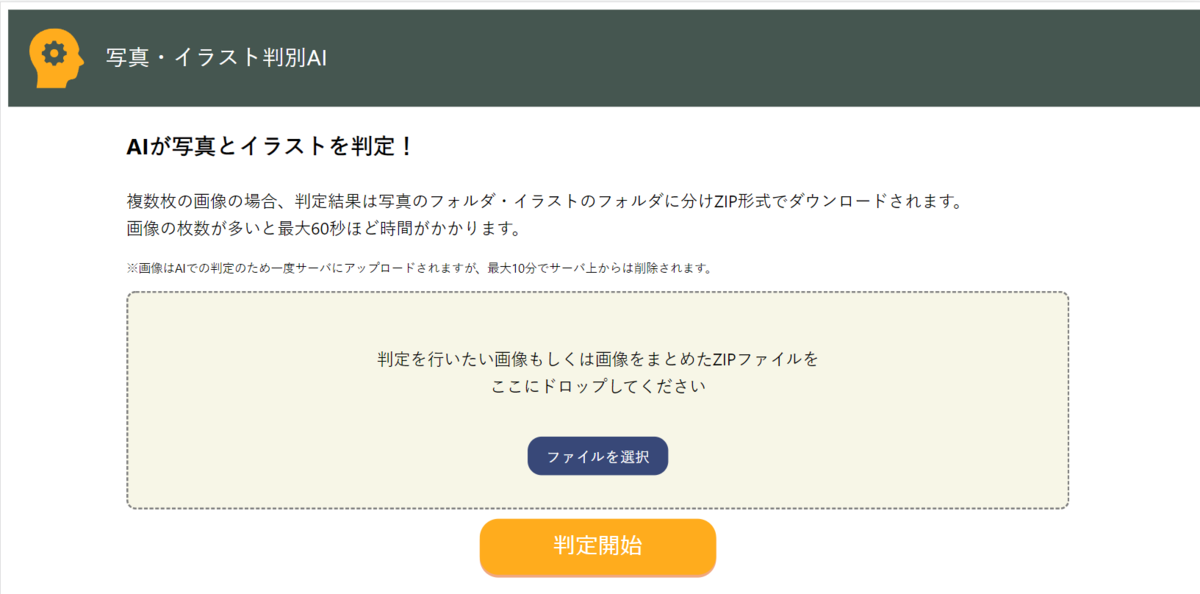
2d3dclassifier.drunkworker.net
シンプルなシングルページのアプリケーションで、できることもシンプル。
- 画像ファイルを単体か、zipファイルでアップロードする
- 「判定開始」ボタンを押して少し待つ
- 画像なら判定結果、zipファイルなら判定結果にフォルダ分けしたzipファイルのダウンロードURLを表示
とこんな感じのWebアプリです。 皆さんぜひ使ってみてください。
需要
個人的には2次元画像と3次元画像を仕分ける需要がめちゃくちゃあったわけなんですよ。皆さんもありますよねぇ??ねぇ?
人の目で何千枚の画像を仕分けるのはしんどいじゃないか、、ということでちょうどたまたま画像分類AIの勉強がてらツールを作ってたら、これ便利なんじゃね?となったのでWebアプリの形にしてみました。
構成

Webアプリの構成はこんな感じです。結構シンプルな構成ですね。
今回は開発環境は基本的にすべてローカルで、アプリの配置関係をすべてAzureに行っています。
構成要素
ローカル
- Anaconda
- Docker
- 最終的に必要なライブラリを記載したrequirements.txtをDockerFileから呼び出して、イメージファイルを作成します。
Azure
- Container Registries
- ローカルで作成したコンテナイメージをContainer RegistriesにPushします。
- ローカルのコンテナイメージをいきなりApp ServicesにDeployしたかったのですが、一度Container Registriesを挟まないとDeployできないようです。
- こいつはおおざっぱに月400円くらいかかります。あまり頻繁にコンテナイメージのPushをしないのであれば都度リソースを消してしまうのがいいかもしれないですね。
- App Servicies
- App Service Plans
- App Servicesの作成時に必ず必要です。これがサーバの実態です。
- 無料プランもありますが、ドメインを設定するためと無料プランだとコンテナイメージの読み込みに毎回3分程度かかってしまって使いものにならないので、最低限のB1というプランに設定しています。
苦労
Azureは結構使うことが多くて多少慣れてはいたのですが、Dockerを使うのは初めてだったので、コンテナイメージをAzureにあげて使うところで結構詰まってしまいました。
この辺の話と解決策についてもどこかのタイミングで書きたいと思います。
今回の内容はここまでとさせてください。
記事の書き方ってこんな感じでいいんですかね?
物欲が止まらない。美味しいものが食べたい。お酒が飲みたい。けど、お金がない
はじめまして、こんにちは
皆様はじめまして、itosssyiと申します。
社会人5年目のサラリーマンです。
月から金まで働いて土日に遊んでます。
コロナのせい?もともとお金ない
コロナが流行し始めて早3年目です。
勤めている会社の業績も悪化してます。直近のボーナスも若干減りました。
だから最近金欠!
ということでもないですね、違いました。もともといつでもお金がなかったんです。
大学生のときは大学の思い出よりもバイト先での思い出のほうが多いのではないかというくらいバイトしてました。思えばあの頃からお金がなかった。
高校生までジーンズメイトの服しか着ていなかったのに大学の途中でおしゃれに興味を持ってしまいました。
おしゃれは悪いことではありません。ですが、如何せん元々おしゃれに興味がなかったものだからどこでどんなものを買えばおしゃれになるのかわからない。
ブランド物は買わずとも毎月5,000~1万くらいの洋服をちょこちょこ買っていました。
お酒が好きになったのもこの頃です。バイト先には色々なお酒がありました。知らないお酒を飲むのが好きでした。
飲み会も好きでした。おしゃべりな性格で、中学、高校、大学、バイト先と色々な人達といつも飲んでました。
こんな生活は社会人になっても変わらずでした。三つ子の魂百までというのはよく言ったもので、20歳の時から一切性格が変わっていない気がします。
社会人になって収入が安定し、少し余裕が出てきたかなと思いましたがそんなことはなかった。まだ実家暮らしだったんです。
ようやく独り立ちをした頃コロナの猛威に襲われます。
幸い仕事はリモートワークでよく、ほとんど家に引きこもっているからお金はそんなに使わないだろうと思ったらこれまた大間違い、
家にいる時間が長いから家の中を便利にしようと色々なものを買いました。
お酒だって飲み会がなくなったけど、家で飲むようになっただけ。
副業禁止だけど頑張ってちょっとでもお金を稼ぎたい。
そんなこんなで、常に金欠な貧乏サラリーマンがどうにか頑張ってお金を稼ごうと頑張るブログを始めてみました。 ブログが稼げるなんて思ってないけど、どこかでこうして意思表明をせねばと思い、こうして初めて記事を書きます。 皆様どうぞよろしくお願いいたします。